Umetnointeligenčna orodja pod sindikalnimi pogoji
22. 5. 2026
Korporativna orodja zbirajo podatke o delavkah in delavcih, digitalni omnibus slabi regulativno zaščito, država pa uvaja umetno inteligenco v javni sektor brez ustreznih varovalk. Poleg tega mnoge aplikacije in platforme, ki jih uporabljamo vsak dan, naše podatke tiho posredujejo ponudnikom za treniranje modelov, pogosto brez naše vednosti. Vse to so razlogi za obrambo. A tokrat gremo v napad: zanima nas, kako si sindikati sami zgradimo orodja umetne inteligence, ki delujejo za nas in ne proti nam.
Splošni jezikovni modeli generativne umetne inteligence (ChatGPT, Claude, Gemini) so trenirani na ogromnih količinah splošnih besedil z interneta. Razumejo pravo, ekonomijo in kadrovske prakse na splošni ravni, a ne poznajo specifičnega slovenskega delovnopravnega okvira, ne poznajo strukture slovenskih kolektivnih pogodb, ne razumejo vedno razlike med kolektivno pogodbo dejavnosti in podjetniško kolektivno pogodbo, ne poznajo aktualnih pogajalskih pozicij sindikatov in ne vedo, kateri zakon ali podzakonski akt ureja določeno pravico v slovenskem kontekstu. Ko sindikalni zaupnik vpraša splošni model za mnenje o tem, ali ima delavka pravico do dodatka za izmensko delo po veljavni kolektivni pogodbi, model praviloma odgovori s splošno razlago, ki je lahko napačna, nepopolna ali zastarela.
To težavo lahko v veliki meri rešimo z orodji, ki jih ponudniki komercialnih modelov že danes ponujajo brezplačno ali v okviru potrošniških naročnin: z izdelavo lastnih agentov, nekakšnih prilagojenih pomočnikov, ki so opremljeni s konkretnim znanjem in konkretnimi navodili za delo.
Kaj je UI agent?
Agent oziroma prilagojeni pomočnik je pravzaprav kombinacija treh sestavin: navodil (ki modelu povedo, kako naj se obnaša, kakšen ton naj uporablja, na kaj naj bo pozoren), znanja (dokumentov, ki jih naložimo v agenta in iz katerih ta črpa informacije pri odgovarjanju) ter modela samega (ki določa, na kakšen način deluje klepetalnik ter koliko ga navodila in znanje usmerjajo v specifično smer).
Izdelava agenta ne zahteva programerskega znanja. Gre za preprosto konfiguracijo, ki jo lahko obvlada vsak: za pisanje navodil v domačem jeziku in za nalaganje dokumentov. Sindikalni zaupnik, ki zna napisati dopis, zna sestaviti tudi svojega agenta.
Oba glavna ponudnika komercialnih klepetalnih robotov, ChatGPT (OpenAI) in Claude (Anthropic), to omogočata že v okviru brezplačnih računov, medtem ko je za agente v Geminiju in Copilotu potrebna naročnina.
- ChatGPT ponuja dva pristopa: Projekte (»Projects«), ki so v bistvu mape za organiziranje pogovorov z deljenim kontekstom in navodili, ter CustomGPT (»Prilagojene GPT«), ki so bolj dovršeni agenti z lastnim imenom, opisom, navodili in bazo znanja, ki jih je mogoče deliti z drugimi uporabniki.
- Claude ponuja Projekte (»Projects«), ki delujejo podobno kot ChatGPT Projekti — nastavimo navodila, naložimo dokumente, in vse pogovore znotraj projekta Claude obravnava v tem kontekstu.
V nadaljevanju bomo korak za korakom pokazali, kako takega agenta izdelamo v obeh orodjih, nato pa predstavili konkreten primer agenta, ki ga že uporabljamo v sindikalni praksi.
Postopek izdelave agentov je podrobno predstavljen tudi v spodnjih video navodilih.
Kako izdelamo agenta ChatGPT?
Projekti (Projects) so na voljo vsem uporabnikom, tudi v brezplačni različici ChatGPT. Gre za enostavnejši pristop, primeren za osebno uporabo, kjer si lahko organizirate svoje delo z enakim sklopom dokumentov in navodil.
- V levem stranskem meniju kliknemo na »Projekti« (»Projects«) in nato na »Nov projekt« (»New project«).
- Projektu damo ime (npr. »Analiza kolektivnih pogodb«).
- V zavihku »Navodila« (»Instructions«) vpišemo, kako naj se model obnaša. Primer navodil za sindikalnega agenta:
»Si pravni pomočnik za sindikalne zaupnike. Odgovarjaš izključno na podlagi naloženih dokumentov: kolektivnih pogodb dejavnosti in podjetniških kolektivnih pogodb. Če odgovora ne najdeš v naloženih dokumentih, to izrecno poveš. Ne izmišljuješ si pravnih določb. Odgovarjaš v slovenščini, v jasnem in razumljivem jeziku, brez nepotrebnega pravniškega žargona. Kadar navajaš določbo, vedno navedi natančen člen, odstavek in ime pogodbe.«
- V zavihku »Datoteke« (»Files«) naložimo dokumente — besedila kolektivnih pogodb v PDF ali Word obliki.
- Vsak nov pogovor, ki ga začnemo znotraj projekta, bo imel dostop do navodil in naloženih dokumentov.
CustomGPT oziroma »Prilagojeni GPT« je bolj dovršen pristop, ki ga ChatGPT omogoča le uporabnikom plačljive različice ChatGPT Plus/Go/Pro (mesečna naročnina). Glavna prednost CustomGPT-jev v primerjavi s Projekti je, da jih je mogoče deliti z drugimi uporabniki, kar pomeni, da lahko sindikat ali sindikalna organizacija izdela enega agenta in ga da na voljo vsem svojim zaupnikom.
- V stranskem meniju kliknemo na meni »GPT-ji« (»My GPTs«) → »Razišči GPT-je« ter v zgornjem desnem kotu »+ Ustvari« (»Create a GPT«).
- Izbiramo lahko med dvema načinoma: »Ustvari« (»Create«), kjer nam ChatGPT v pogovoru pomaga oblikovati agenta, ali »Konfiguracija« (»Configure«), kjer sami vpišemo vse parametre.
- V zavihku »Nastavi« izpolnimo:
- Ime (»Name«): na primer »Sindikalni pravni pomočnik«.
- Opis (»Description«): kratek opis namena agenta.
- Navodila (»Instructions«): enako kot pri projektu – navodila za obnašanje, ton, omejitve.
- Znanje (»Knowledge«): tu naložimo dokumente, iz katerih agent črpa.
- Zmogljivosti (»Capabilities«): izberemo, ali ima agent dostop do spleta, do orodja za analizo podatkov ali do generiranja slik. Za sindikalno analizo pogodb praviloma potrebujemo le privzete zmogljivosti.
- Kliknemo »Shrani« (»Save«) in izberemo, ali je agent dostopen le nam, vsem z neposredno povezavo ali javno.
- Vsak nov pogovor, ki ga začnemo znotraj projekta, bo imel dostop do navodil in naloženih dokumentov.
Opozorilo: Pri CustomGPT, ki ga delimo z drugimi, velja enaka previdnost kot pri vseh komercialnih orodjih. Dokumenti, ki jih naložimo v bazo znanja, so shranjeni na strežnikih OpenAI. V bazo znanja ne nalagamo dokumentov z občutljivimi osebnimi podatki, temveč le javno dostopna besedila (objavljene kolektivne pogodbe, zakone, pravilnike). Za obdelavo občutljivih primerov uporabimo anonimizacijo, kot smo jo opisali v praktičnem priročniku.
Kako izdelamo agenta Claude?
Claude ponuja Projects (Projekte), ki so funkcionalno podobni ChatGPT Projektom in so na voljo tudi v brezplačni različici (z določenimi omejitvami glede števila pogovorov).
- V levem stranskem meniju kliknemo na »Projects« (Projekti) in nato na »Create project« (Ustvari projekt).
- Projektu damo ime in kratek opis.
- V razdelku »Set project instructions« (Nastavi navodila projekta) vpišemo navodila — enako logiko kot pri ChatGPT, le da Claude navodila obravnava v polju »Custom instructions«. Primer:
»Si pomočnik za pisanje dopisov. Te pripravljaš izključno na podlagi vnesenih informacij ter vzorčnega dokumenta, naloženega v dokumente. Če specifične informacije ne najdeš, vprašaj, ali bo uporabnik to naložil. Dopise vedno pripravljaš v slovenščini. Pri navajanju določb zakonov vedno vprašaj, iz katerega vira jih navajaš. Končni dokument oblikuj, ko boš imel na voljo vse informacije. Takrat vprašaj: »Ali lahko oblikujem končni dokument? Točnost danih informacij vedno dvakrat preveri, preden jih zapišeš.«
- V razdelku »Files« (Dokumenti) naložimo dokumente v PDF ali Word obliki oziroma izberemo možnost »Add text content« (Dodaj besedilo), kjer lahko besedilo neposredno dodamo s kopiranjem iz dokumenta ali s spletne strani.
- Vsak nov pogovor, ki ga začnemo znotraj projekta, bo imel dostop do navodil in naloženih dokumentov.
Prednost Clauda je, da podjetje Anthropic privzeto ne uporablja klepetov potrošniških računov za treniranje modelov. Toda enako opozorilo velja: v bazo znanja ne nalagamo dokumentov z občutljivimi osebnimi podatki. Nalagamo javno dostopna besedila, za konkretne primere pa uporabljamo anonimizacijo, če je ta mogoča.
Primer iz prakse: Agent za analizo kolektivnih pogodb
V ZSSS smo v plačljivem računu ChatGPT Business izdelali CustomGPT za analizo kolektivnih pogodb dejavnosti (KpD) in podjetniških kolektivnih pogodb (PKP). Agent je bil zasnovan z jasnim namenom: sindikalnim zaupnikom in zaupnicam, članom in članicam omogočiti hitro iskanje, primerjavo in razlago določb iz veljavnih kolektivnih pogodb, ne da bi morali ročno preiskati obsežna besedila. Na voljo sta dva agenta, eden za analizo, pregled in primerjavo KpD ter PKP v zasebnem sektorju in drugi za analizo, pregled in primerjavo KpD ter PKP v javnem sektorju.
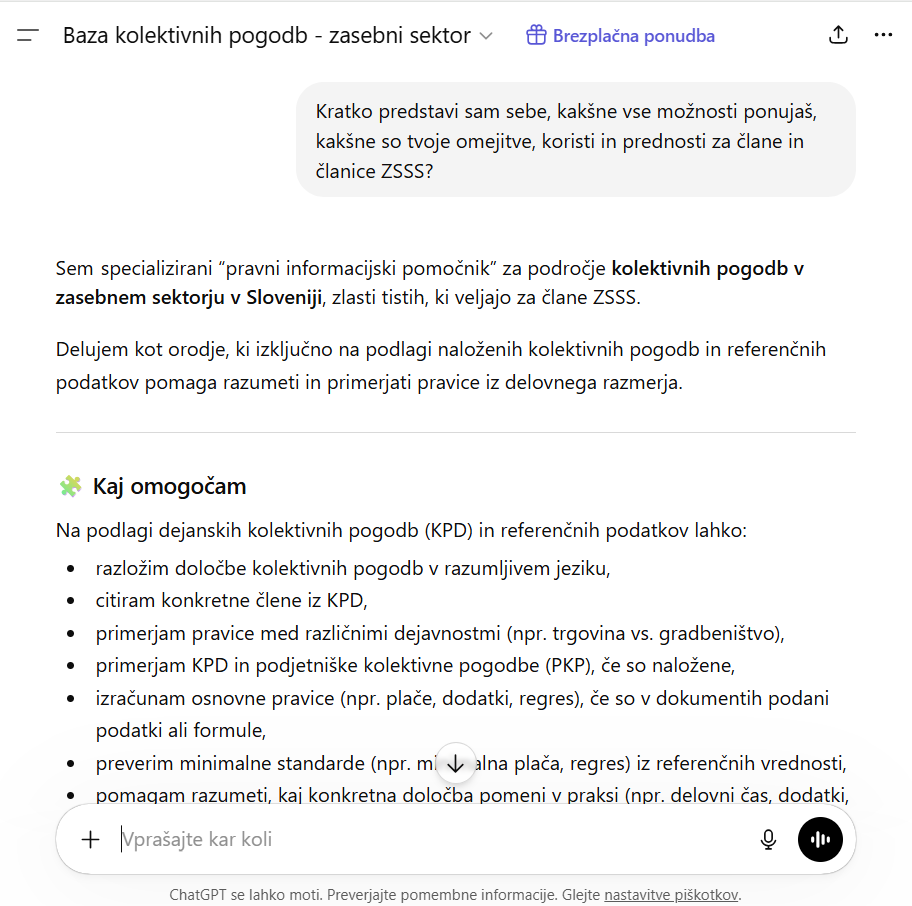
Navodila za agenta Baza kolektivnih pogodb (v zasebnem in javnem sektorju) so bila ustvarjena s pomočjo klepetalnika ChatGPT, nato pa z natančnim prilagajanjem dodatnih nastavitev ter s številnimi praktičnimi preizkusi umerjena tako, da agent ponuja čim bolj relevantne odgovore.
Tak agent seveda ni nadomestilo za pravno svetovanje, je pa izjemno uporaben za hiter pregled, za iskanje relevantnih določb, za primerjavo formulacij med različnimi pogodbami in za pripravo izhodišč za pogajanja. Ključna prednost je, da agent odgovarja na podlagi dejanskih besedil pogodb, ki smo mu jih naložili, ne pa na podlagi splošnih informacij z interneta, ki so pogosto napačne ali zastarele. Hkrati pa primer pokaže tudi mejo komercialnih orodij: agent deluje le tako dolgo, dokler ZSSS plačuje naročnino za ChatGPT, in vsi dokumenti, ki jih je v agenta naložil ustvarjalec, so doma na strežnikih podjetja OpenAI na Irskem.
Zakaj potrebujemo odprtokodne alternative?
Opisani pristop – izdelava agentov v komercialnih orodjih – je uporaben in dostopen že sedaj. A ima tri sistemske omejitve, ki jih sindikati ne smemo spregledati:
- Prvič, podatki ostajajo pri ponudniku in suverenost je iluzorna. Tudi ob najstrožjih nastavitvah zasebnosti dokumenti, ki jih naložimo v CustomGPT ali v Claude Projekt, fizično ležijo na strežnikih ameriških podjetij. Njihove politike zasebnosti se lahko spremenijo z naslednjo posodobitvijo pogojev uporabe, brez naše privolitve. Za sindikalno organizacijo, ki obdeluje občutljive pravne in osebne podatke, je to dolgoročno nesprejemljivo. Suverena alternativa bi pomenila, da lahko sindikalna ali nevladna organizacija oziroma javna institucija model naloži na lastno strojno opremo in z njim ravna po lastnih pravilih. Te alternative sedaj v komercialnih orodjih ni. Na to se navezuje drugo pomembno dejstvo, ki smo ga obravnavali v drugem prispevku te tematske številke: veliki komercialni modeli so bili trenirani brez izrecnih dovoljenj založnikov in avtorjev. Sodni spor med The New York Times in OpenAI se vrti ravno okoli tega vprašanja. To pomeni, da sindikalna organizacija, ki uporablja komercialna orodja, posredno legitimira poslovni model, ki temelji na množični kršitvi avtorskih pravic, vključno z avtorskimi pravicami slovenskih avtorjev, novinarjev in raziskovalcev.
- Drugič, modeli se spreminjajo brez naše vednosti. OpenAI in Anthropic redno posodabljata splošne modele. Sprememba, ki izboljša splošno zmogljivost, lahko hkrati poslabša natančnost pri specifičnih nalogah: denimo pri razlagi slovenskih pravnih besedil. Sindikalna organizacija, ki se zanaša na komercialnega agenta, nima vpliva na te spremembe in nima zagotovila, da bo agent jutri deloval enako kot danes.
- Tretjič, cene se spreminjajo brez našega nadzora. Funkcionalnosti, ki so danes vključene v potrošniško naročnino, so lahko jutri na voljo le v podjetniških paketih. Sindikalna organizacija, ki zgradi celoten delovni proces okoli komercialnega orodja, je ranljiva za spremembe cenovnih politik.
- K tem trem omejitvam je treba dodati še jezikovne omejitve: vsi veliki komercialni modeli so v veliki večini trenirani na angleških besedilih, slovenski jezik pa je v njihovih učnih zbirkah le obrobno zastopan, kljub temu da so izjemno sposobni prevajalci. To pomeni, da pri obravnavi slovenskih pravnih besedil in specifičnih jezikovnih registrov pogosto delajo napake; od nepravilnih sklanjatev do napačnega razumevanja pravne terminologije. Splošni model, treniran na slovenskem jeziku v ustreznem obsegu, bi za sindikalno rabo deloval bistveno bolj zanesljivo.
Slovenski projekti, ki že gradijo alternativne pristope
Dobra novica je, da v Sloveniji že obstajata dva pomembna projekta, ki gradita infrastrukturo za odprto in slovensko zasnovane jezikovne tehnologije. Projekt PoVeJMo je raziskovalno-inovacijski program, v katerem sodelujejo Center za jezikovne vire in tehnologije Univerze v Ljubljani (CJVT), Fakulteta za računalništvo in informatiko Univerze v Ljubljani (FRI), Inštitut za novejšo zgodovino in ZRC SAZU. Cilj projekta je razvoj odprtokodnih velikih jezikovnih modelov za slovenščino.

V njegovem okviru je v intenzivnem razvoju model GaMS pod vodstvom prof. dr. Marka Robnika Šikonje. Kot je v nedavnem intervjuju za Svet24 omenil Šikonja, je GaMS med vsemi javno dostopnimi modeli za zdaj najuspešnejši pri obravnavi dvajsetih evropskih jezikov, vključno s slovenščino. Ključno za sindikalno gibanje pa je drugo dejstvo: razvoj modela se izvaja v skladu z evropsko zakonodajo o avtorskih pravicah. Razvijalci so za vključitev posameznih komercialnih virov v učne zbirke pridobili izrecna dovoljenja; med drugim časopisne hiše Dnevnik in Slovenske tiskovne agencije.
To je popolno nasprotje poslovnega modela ameriških gigantov, ki so po podatkih žvižgačev za treniranje uporabljali tudi piratizirane vsebine. Za izgradnjo zmogljivega modela projekt potrebuje 40 milijard besed v slovenščini in trenutno poteka nacionalna zbiralna akcija, v okviru katere lahko ustanove in posamezniki posredujejo svoja besedila. Do pomladi 2026 je bilo zbranih okoli 9,2 milijarde besed, torej slaba četrtina potrebnega obsega.
ZSSS bi lahko po pravilih projekta posredovala svoja javno objavljena gradiva: analize, poročila, javne pozive, in s tem prispevala k oblikovanju modela, ki bo razumel tudi sindikalno govorico.
Projekt LLM4DH, ki poteka od 2022 do 2027 in ga financira Agencija za raziskovalno dejavnost Slovenije (ARIS), raziskuje uporabo velikih jezikovnih modelov za potrebe digitalne humanistike. Vključuje šest projektnih sklopov, med drugim razvoj metod za izboljšanje jezikovnih modelov z jezikovnimi viri, razvoj modelov za govorjeni jezik in evalvacijo modelov. To je natančno tisti tip raziskovalne infrastrukture, ki je potrebna za razvoj specializiranih agentov za sindikalno rabo.
Na to se navezujeta dva načrtovana infrastrukturna premika, ki bosta v naslednjih letih pomembno spremenila slovensko podatkovno suverenost. Prvi je vzpostavitev slovenske tovarne umetne inteligence v Mariboru, kjer bo leta 2027 zaživel superračunalnik Vega 2. Ta bo prvič omogočil, da se slovenski jezikovni modeli trenirajo na domači strojni opremi (doslej je bil model GaMS treniran na superračunalniku Leonardo v italijanski Bologni).
Drugi premik je evropska iniciativa Open EuroLLM, ki naj bi v enem letu ponudila konkurenčne odprtokodne modele, sicer manjše od ameriških komercialnih, a takšne, da jih bodo lahko evropska podjetja in javne institucije namestile na lastno strojno opremo. Razvijalci slovenskega modela GaMS so v Open EuroLLM aktivno vključeni. Skupni evropski vložek v tovrstne projekte je sicer drobiž v primerjavi z ameriškimi vlaganji – Open EuroLLM razpolaga z okoli sto milijoni evrov, medtem ko ameriška podjetja v razvoj umetne inteligence vlagajo stotine milijard dolarjev –, a prav v majhnosti je prebojna možnost: evropski modeli ne tekmujejo na področju splošnosti, temveč na področju suverenosti.
CJVT je vzpostavil tudi Slovensko pogovorno areno, platformo, kjer se uporabniki lahko pogovarjajo z različnimi velikimi jezikovnimi modeli v slovenščini in jih primerjajo med sabo. To je odlično orodje, s katerim se lahko sindikalni zaupniki sami prepričajo, kateri modeli najbolje obvladajo slovenski jezik in slovenske pravne teme, in s svojim ocenjevanjem pomagajo k njihovemu izboljšanju.
Sindikati moramo sodelovati pri razvoju odprtokodnih orodij
Sindikati ne smemo stati križem rok v abstraktnem pozivu k razvoju lastnih orodij, temveč moramo predlagati konkretne korake:
- Prvič, ZSSS naj pristopi k pogovoru z vodstvom projekta PoVeJMo in razišče, kako lahko sindikalno gibanje prispeva k razvoju slovenskega jezikovnega modela. Tak pogovor lahko poteka v dveh smereh: kot prispevek besedil v zbiralno akcijo in kot sodelovanje pri zasnovi specializiranih agentov za sindikalno in pravno rabo. Da to ni utopična ideja, dokazujejo aplikacije, ki so jih raziskovalci s pomočjo modela GaMS že razvili: sistem za prepis zdravnikovega nareka v realnem času z avtomatskim preverjanjem ustreznosti predpisanih zdravil, interaktivni muzejski vodniki, ki obiskovalcem prek slušalk samodejno odgovarjajo na vprašanja o eksponatih, in sistemi za prepoznavanje govora v hrupnih industrijskih okoljih za delavce iz različnih jezikovnih okolij.
- Drugič, ZSSS naj podpre vključitev delavske perspektive v evalvacijo modelov, ki poteka na Slovenski pogovorni areni in v okviru projekta LLM4DH. To pomeni, da sindikalni pravniki in zaupniki sistematično preizkušajo modele na konkretnih sindikalnih vprašanjih in svoje ocene posredujejo raziskovalcem. S tem zagotovimo, da bodo modeli, ki jih razvijajo slovenske univerze, dejansko ustrezali tudi potrebam delavskega gibanja, ne le potrebam podjetniške in akademske sfere.
- Tretjič, ZSSS se mora vključiti v javno razpravo o jezikovni politiki in digitizaciji. Kot je nedavno opozorila znanstvena javnost, slovenski jezikovni modeli ne morejo doseči svojih ciljev brez ustrezno digitiziranega sodobnega gradiva (kar je naloga Narodne in univerzitetne knjižnice in ministrstva za kulturo) in brez jasne zakonodaje, ki bo razrešila vprašanja avtorskih pravic pri treniranju modelov.
Politični premiki v tej smeri (na primer napoved nekdanjega predsednika vlade dr. Roberta Goloba, da bo Slovenija prva država z brezplačnim dostopom do orodij umetne inteligence) odpirajo prostor za to, da se sindikalno gibanje vključi kot pomemben udeleženec v razpravo o tem, kakšna umetna inteligenca v slovenskem jeziku bo v prihodnje na voljo.
Vse to je dolgoročno delo, ki bo trajalo več let. A če se sindikati v tem trenutku ne vključimo v sodelovanje s slovenskimi raziskovalnimi institucijami, bomo čez nekaj let ugotovili, da je infrastruktura za umetno inteligenco v Sloveniji zgrajena brez našega strokovnega znanja in udeležbe. Prisiljeni bomo uporabljati orodja, ki niso bila nujno zasnovana za naše potrebe in v našem interesu. Danski model, ki smo ga omenili v enem prejšnjih člankov, ni nastal čez noč in tudi slovenski ne bo. A nastane lahko le, če ga začnemo graditi danes.
Miha Poredoš





